
#8 - August 2025
Themen in dieser Ausgabe:
- Neuigkeiten
- Vom Suchen und Finden der richtigen Daten
- Bedeutende Frauen der Informatik: Karen Spärck Jones
- Links und Leseempfehlungen
- Neulich im Podcast & im Internet
- Last, but not least
Hallo ,
ich hoffe, dass du die warmen Sommertage im August genießen konntest. Hier in Karlsruhe war es an ein paar Tagen leicht über meiner Wohlfühltemperatur. Aber ich möchte mich nicht beschweren. Das sonnige Wetter liegt mir persönlich mehr, als der Regen und die Dunkelheit, die uns zum Ende des Jahres erwarten. Leider hat mich zum Ende des Monats noch meine dritte oder vierte Erkältung in diesem Jahr erwischt. Ich hoffe, dass dies jetzt wirklich die letzte größere Erkrankung in diesem Jahr war.
Vor einigen Tagen hat mich eine Nachricht von meinem Podcastfreund Poldi erreicht. Er betreibt den Retrogaming Podcast Pixelbeschallung und der war bisher direkt bei Spotify gehostet. Das ist ein kostenloser Service, der von Spotify ziemlich intensiv beworben wird und der nur Vorteile haben soll. Dort gehostete Podcasts sind dann übrigens nicht nur exklusiv bei Spotify, sondern auch noch zusätzlich via RSS Feed erreichbar. Ein scheinbar gutes Angebot.
Doch der Teufel steckt in den Details. Denn Poldi hatte auch eine kleine Sommerpause und dafür eine Spezialepisiode produziert. Und diese bestand aus 10 eigens erstellten KI Songs, die sich thematisch rund um die bunte Welt der Retrogames drehten. Doch leider hatte Poldi die Rechnung ohne Spotify gemacht. Denn in den AGBs werden solche "Jukebox Episoden" nicht geduldet. Und aus diesem Grund löschte Spotify den kompletten Podcast mit über 150 Episoden.
Poldi versuchte vergeblich, Spotify umzustimmen oder zumindest wieder Zugriff auf seinen Feed zu bekommen. Aber daraus wurde leider nichts. Und so blieb ihm keine Alternative, als komplett neu mit 0 Abonenten zu starten. Denn dadurch, dass der Podcast direkt bei Spotify gehostet war, führte auch die Feed URL zu Spotify. Und ohne administrativen Zugriff darauf ist es leider nicht möglich, den Feed auf eine neue URL zumzuziehen.
Diese Geschichte machte mich nachdenklich. Das Internet konzentriert sich auf immer mehr große Unternehmen. Und je mehr wir diesen vertrauen, desto abhängiger sind wir von ihren Regeln. Und bei einem Verstoß entscheiden die Plattformen, wie sie damit umgehen. Das ist keine Begegnung auf Augenhöhe. Klar, Poldi hat eindeutig einen Fehler gemacht. Aber ist es dann gerechtfertigt, das jahrelang aufgebaute Hobbyprojekt direkt zu löschen? Oder hätte es an der Stelle nicht auch eine Verwarnung getan?
Mich hat diese Vorfall daran bestärkt, mich mehr um meine eigene digitale Souveränität zu kümmern. Und das fängt schon bei kleinen Dingen an. Bei der Wahl des Mailanbieters oder Hosters. Viele Dinge kann man selbst betreiben, bzw. hosten. Zum Beispiel einen Blog oder Podcast. Und im Zweifel scheint mir das die bessere Alternative zu sein.
Wie seht ihr das? Schreibt mir das gerne per Mail oder schaut doch mal im Discord vorbei. Und falls ihr den Podcast von Poldi nicht kennt, dann hört euch gerne mal eine Episode der Pixelbeschallung an.
Diese Ausgabe der Anomalie dreht sich um das Suchen und Finden von Daten. Wie funktioniert eigentlich eine Suchmaschine? Und wie gelangen die besten Treffer auf Platz 1? Und weil es thematisch gut passt habe ich noch die Geschichte von Karen Spärck Jones mitgebracht. Sie hat nämlich einen großen Beitrag dazu geleistet.
Ich wünsche dir viel Spaß beim Lesen und einen tollen September!
Wenn du Feedback für mich hast, kannst du mir gerne direkt auf diese Mail antworten.
Herzliche Grüße
Wolfgang
Vom Suchen und Finden der richtigen Daten
Wie findet man eigentlich die richtige Webseite zu einem Suchbegriff? Klar, in der heutigen Zeit fragt man einfach einen KI Assistenten oder man tippt die Frage noch oldschool bei Google ein. Aber wie funktioniert das technisch? Wie kann man eine Webseite oder vielleicht etwas allgemeiner gesprochen ein Dokument unter vielen Milliarden Dokumenten finden, das am besten zu einem oder mehreren eingegeben Suchbegriffen passt?
Diese Frage beschäftigt die Menschheit schon, seit Informationen irgendwie aufgeschrieben werden. Und sie ist heute noch relevanter als je zuvor. Denn die Menge an Dokumenten steigt stetig an. Das können Webseiten, Dateien oder digitalisierte Bücher sein.
Das gezielte Auffinden der richtigen Dokumente ist elementar wichtig. Man spricht hier auch vom sprichwörtlichen Heben eines Schatzes aus dem Ozean der Informationen.
Die Fachdisziplin, die sich mit dem Wiederfinden von Daten beschäftigt, nennt sich Information Retrieval und in dem Bereich habe ich damals auch meine Diplomarbeit geschrieben und die nachfolgenden Jahre gearbeitet. Mich interessierte damals vor allem das Thema Volltextsuche und ich durfte in verschiedenen Projekten für Unternehmen Suchmaschinen entwickeln, die analog zu Google die jeweils besten Treffer zu eingegebenen Suchbegriffen finden. Nur waren es in meinem Fall keine Webseiten, sondern Produkte in Onlineshops, Dokumente im Intranet oder auch Filme und Serien auf einem Streamingportal.
Gut, aber wie funktioniert sowas? Lasst uns auf eine kleine Reise durch die Geschichte der Volltextsuche gehen. Wenn man herausfinden möchte, welches Dokument aus einer Sammlung von Dokumenten am besten zu einem Suchbegriff passt, dann muss man zunächst klären, was das eigentlich bedeutet. Wir Menschen haben natürlich einen sehr intuitiven Zugang zu solchen Fragen. Wir lesen Dokumente und entscheiden dann auf Grund unseres Wissens und unserer Erwartungen, ob ein Dokument passt oder nicht. Für einen Computer müssen wir sowas messbar machen und klar definieren können.
Inverse Document Frequency (IDF)
Die ersten Forschungen und mathematischen Grundlagen zur statistischen Analyse von Texten wurden in den 1950er und 1960er Jahren gelegt. Im Jahr 1972 veröffentliche dann die Informatikerin Karen Spärck Jones eine Arbeit zu einer Metrik namens Inverse Document Frequency (IDF). Eine Metrik ist eine mathematische Kennzahl. Und diese Arbeit hatte es in sich. Spärck Jones beschreibt darin eine Formel, mit der man bestimmen kann, wie selten und damit wertvoll, bzw. wichtig ein Begriff innerhalb einer Dokumentensammlung ist. Wichtiger als die Mathematik sind die Kerngedanken:
Häufig vorkommende Begriffe erhalten einen IDF-Wert nahe 0
Sehr selten vorkommende Begriffe erhalten höhere IDF-Werte (oft größer als 1)
mittelhäufig vorkommende Begriffe erhalten einen Wert zwischen 0 und 1
Die Häufigkeit bezieht sich dabei jeweils darauf, in wie vielen Dokumenten der Begriff vorkommt. Die IDF sorgt dafür, dass sehr häufige Begriffe wie “und, ich, oder” einen extrem geringen Wert haben, während Begriffe wie Quantencomputer oder Eichhörnchenkobel einen höheren Wert bekommen.
Die ursprüngliche Formel zur Berechnung der IDF ist die folgende wobei t der jeweilige Begriff und D die Dokumentensammlung ist:
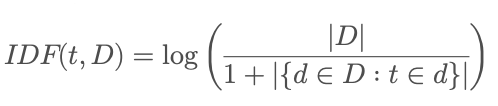
Term Frequency (TF)
Für unsere Volltextsuche benötigen wir nun noch eine weitere Metrik und das ist die Term Frequency (TF). Diese beschreibt die Häufigkeit eines Begriffs innerhalb eines einzelnen Dokuments. Der Gedanke dahinter: Je häufiger ein Begriff in einem Dokument vorkommt, desto wichtiger ist der Begriff für dieses Dokument. Dafür werden die Vorkommen des Begriffs einfach gezählt und durch die Anzahl aller Begriffe im Dokument geteilt.
Und auch dafür habe ich die Formel für euch. Hierbei ist t wieder der Begriff und d steht für das einzelne Dokument.

Die Kombination: TF-IDF
Gut, aber irgendwie sind diese beiden Berechnungen alleine genommen noch nicht so ganz hilfreich. Das ändert sich aber, wenn man sie kombiniert und so die TF-IDF-Metrik entsteht. Dafür multipliziert man einfach beide Werte miteinander.
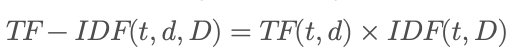
Dadurch werden jetzt Begriffe, die in allen Dokumenten sehr häufig vorkommen, generell abgewertet, während eher seltene Begriffe aufgewertet werden. Konkret für ein einzelnes Dokument bedeutet das, dass sehr häufige Begriffe wie “und, oder, in, im” zwar eine hohe TF haben, aber eine geringe IDF und daher auch eine geringe TF-IDF. Seltene Begriffe wie Quantencomputer haben vielleicht eine eher geringe TF, werden aber durch ihre hohe IDF stark aufgewertet und bekommen damit auch eine hohe TF-IDF. Und so werden die Begriffe mit einer hohen TF-IDF charakteristisch für die jeweiligen Dokumente, da sie ja generell selten, aber in einer höheren Konzentration im jeweiligen Dokument vorkommen. Und genau diese Dokumente möchte man doch finden, wenn man nach einem Quantencomputer sucht.
Der invertierte Index
Für eine einfache Suchmaschine braucht man dann nicht mehr viel. Eigentlich nur noch eine einfache und effiziente Art, um von den Suchbegriffen jeweils die Dokumente zu finden, die am besten passen. Dafür nutzt man einen invertierten Index. Das kennt ihr entweder vom Telefonbuch oder aus dem Stichwortregister eines Sachbuchs. Beim invertierten Index handelt es sich um eine alphabetische Liste aller Begriffe aus allen Dokumenten. Zu jedem Begriff ist notiert, in welchen Dokumenten er vorkommt und wie der jeweilige TF-IDF dazu ist. Und in solchen sortierten Listen kann man blitzschnell suchen - auch wenn sie extrem groß sind.
Sucht man nicht nur nach einem, sondern nach zwei oder mehr Begriffen, dann funktioniert das erstmal alles genauso, nur dass nach dem Nachschlagen im invertierten Index geschaut wird, welche Dokumente bei allen Begriffen vorkommen. Sowas kann ein Computer auch extrem schnell machen.
Von TF-IDF zu modernen Suchmaschinen
In der Praxis würde eine Suchmaschine natürlich nicht nur einen invertierten Index und eine TF-IDF Metrik verwenden, sondern noch eine Menge an Vorverarbeitungsschritten und Optimierungen durchführen. So würden beispielsweise irrelevante Stop Words (Stoppwörter – also sehr häufige, aber meist irrelevante Wörter) wie “und, oder, in, im” entfernt, Begriffe normalisiert indem sie kleingeschrieben und auf ihre Grundformen zurückgeführt werden. Außerdem könnte man bei der Festlegung des Rankings, also der Ergebnisreihenfolge nicht nur auf den TF-IDF Wert setzen, sondern auch bewerten, wo die gesuchten Begriffe im Dokument vorkommen. Und so beispielsweise Treffer in Überschriften höher gewichten. Bei Google kam damals dann noch der PageRank hinzu, der berücksichtigte, wie viele eingehende Links eine Webseite hat und daraus schlussfolgerte, wie bedeutend sie eigentlich ist. Denn - so war die Idee - auf eine wichtige Seite verlinken auch viele Seiten und das zeigt schön die demokratischen Strukturen des frühen Webs – auch wenn dieses Ideal schnell durch SEO und Spam herausgefordert wurde.
Dieses Search Engineering ist eine Kunst und teils Firmengeheimnis, teils aber auch von Alchemie nicht so recht zu unterscheiden. Und auch wenn heute fast überall KI im Einsatz ist – der Grundgedanke bleibt derselbe. Das TF-IDF Verfahren oder zumindest die Ideen daraus werden heute immer noch verwendet. Auch wenn natürlich überall KI eingesetzt wird. Ein großer Vorteil der klassischen Verfahren ist ihre enorme Geschwindigkeit bei gleichzeitig geringen Ressourcenanforderungen.
Moderne Suchmaschinen mit Vektormodellen und neuronalen Netzen gehen einen Schritt weiter und können auch Synonyme oder ganze Kontexte erfassen. Aber letztlich stehen sie in der Tradition von TF-IDF: Am Ende geht es immer darum, aus einer unüberschaubaren Flut an Informationen die wenigen relevanten Schätze zu heben.
Quellen
- TF-IDF in der Englischen Wikipeda
- Übersichtsartikel zu Information Retrival in der Wikipedia
- Ein TF-IDF Simulator
Bedeutende Frauen der Informatik: Karen Spärck Jones
 Im Artikel über die TF-IDF-Metrik habe ich die Informatikerin Karen Spärck Jones erwähnt. Es lohnt sich, einen Blick in ihre Geschichte zu werfen und das Leben einer bemerkenswerten Frau zu entdecken.
Im Artikel über die TF-IDF-Metrik habe ich die Informatikerin Karen Spärck Jones erwähnt. Es lohnt sich, einen Blick in ihre Geschichte zu werfen und das Leben einer bemerkenswerten Frau zu entdecken.
Geboren wurde sie 1935 in Huddersfield, England als Tochter einer nach England ausgewanderten Norwegerin und eines Engländers. Zu Schulzeiten interessierte sie sich schon für Naturwissenschaften. Zur damaligen Zeit waren die Schulen in England so organisiert, dass man zwischen einer naturwissenschaftlichen und einer geisteswissenschaftlichen Richtung wählen musste. Spärck Jones entschied sich für die Naturwissenschaften, wobei sie für die anderen Fächer auch ein großes Interesse hatte.
Schon als junges Mädchen hatte sie den Wunsch, nach der Schule in Cambridge zu studieren. Sie verfolgte diesen Wunsch zielstrebig. Als es dann um die Wahl eines Studienplatzes ging, entschied sie sich nicht für eine Naturwissenschaft, sondern für Geschichte und Philosophie. Schon damals war ihr Interesse sehr breit. Rückblickend kann man sicher sagen, dass ihr dieses breite Wissen dabei half, in ihrer späteren Arbeit die Brücke zwischen Sprache und Technik zu schlagen. Ihre Fähigkeit, Sprache nicht nur als Mittel der Kommunikation, sondern auch als formale Struktur zu begreifen, wurde zur Grundlage ihrer Forschung.
Ihre Forschungsarbeit begann sie in der Gruppe Cambridge Language Research Unit (CLRU). Und das war für sie auch der Wendepunkt, an dem sich ihre Arbeit zunehmend mit der Informatik beschäftigte. Genauer gesagt beschäftigte sie sich mit Computerlinguistik. Damals war die Idee, dass Maschinen menschliche Sprache verarbeiten und verstehen können, noch neu und wurde von vielen belächelt. Computer galten als Rechenmaschinen – nicht als Sprachversteher. Spärck Jones aber war überzeugt: Wenn Computer jemals wirklich nützlich sein sollten, müssten sie Texte und Dokumente so verstehen können, dass Menschen die gesuchten Informationen schnell finden.
Karen Spärck Jones hatte nie ein Informatikstudium abgeschlossen und sich das Programmieren selbst ohne Zugriff auf einen eigenen Computer beigebracht. Sie hatte im Alter von 15 Jahren aufgehört, sich mit Mathematik zu beschäftigen und später Geschichte und Philosophie studiert. Dennoch – oder gerade deswegen – war sie genau die richtige Person zur richtigen Zeit, um mit frischen Ideen das junge Forschungsfeld voranzubringen. Ihre frühe Forschung im CLRU bildete die Basis für ihre Promotion mit dem Titel Synonymy and semantic classification, die sie 1964 erfolgreich abschloss.
Spärck Jones war bis zum Ende ihres Lebens als Forscherin in Cambridge angestellt. Allerdings erst seit 1999 mit einer festen Professur. Zuvor waren ihre Stellen immer nur durch befristete Drittmittel finanziert worden – über Jahrzehnte hinweg. Ein Problem, das viele männliche Kollegen – einschließlich ihres Ehemannes – nicht hatten. Vielleicht war das auch ein Grund dafür, warum sie sich für Frauen in der Forschung einsetzte.
Denn Spärck Jones war nicht nur eine brillante Forscherin, sondern auch eine kluge Beobachterin der Gesellschaft. In einer Zeit, in der Frauen in der Informatik fast unsichtbar waren, machte sie sich für mehr Diversität stark. Ihr bekanntestes Zitat bringt das sehr klar auf den Punkt:
„Computing is too important to be left to men.“
Für ihre Leistungen erhielt sie zahlreiche Auszeichnungen, darunter die Lovelace Medal der British Computer Society. 2008 – ein Jahr nach ihrem Tod – wurde sie in die Royal Society aufgenommen, eine der höchsten wissenschaftlichen Ehrungen in Großbritannien.
Karen Spärck Jones starb 2007. Ihre Ideen leben jedoch fort – in jeder Internetsuche, in jeder Textanalyse und auch in modernen Sprachmodellen. Sie hat die Informatik nicht nur mit wichtigen Konzepten bereichert, sondern auch gezeigt, dass Technik immer etwas mit Sprache, Kultur und Menschen zu tun hat.
Quellen
- Ausführliches Interview mit ihr beim IEEE History Center
- Artikel über sie in der Wikipedia
- Artikel über sie bei Golem.de
- Review zu ihrer Promotionsschrift
- Interview beim bcs Institute
- Das Foto stammt von der xxx und steht unter der CC BY 2.5 Lizenz
{kind=link}
Links und Leseempfehlungen
Primzahlen haben die Menschen schon immer fasziniert. Naja, zumindest alle, die Interesse an Mathematik oder Zahlenmystik hatten. Das Prime Grid ist eine schöne Visualisierung von Mustern, basierend auf Primzahlen.
Email is easy! Oder etwa doch nicht? Diese kleine Quiz zeigt, die absurd die Email Spezifikation eigentlich ist. Wieviele Punkte schaffst du? Bei mir waren es 10. Und falls du auf den Geschmack gekommen bist und gerne programmierst, dann schaue dir doch mal an, wie man Emailadressen mit einem regulären Ausdruck prüfen kann. Also zumindest fast.
KI in den 1980ern Ich bin über dieses Video (YouTube) aus dem Jahr 1986 gestolpert. Darin wird über künstliche Intelligenz gesprochen. Und ich finde es erstaunlich, wie relevant das auch heute noch ist.
Neulich im Podcast & im Internet
Digitale Anomalien #109: Nur ganz leicht falsch

Im Jahr 2013 deckte der Informatiker David Kriesel einen schwerwiegenden Fehler in einigen Multifunktionsgeräten von Xerox auf. Dieser führte dazu, dass es in eingescannten Dokumenten zu Zahlendrehern kommen konnte, die jedoch nicht ohne Weiteres als solche erkennbar waren.
Ursache war eine fehlerhaft implementierte Kompressionsmethode. Zum Zeitpunkt der Veröffentlichung dieser Geschichte waren die betroffenen Geräte bereits seit acht Jahren auf dem Markt.
Digitale Anomalien #110: Die Mondverschwörung
 In der letzten Folge hatte ich erwähnt, dass es bei Samsung einmal einen Fall gab, bei dem Mondfotos durch Stockfotos ersetzt wurden. Doch das stimmt so nicht. In dieser Folge geht es um die Frage, was es mit den Mondfotos auf sich hat. Und dabei kommt auch zwangsläufig die Frage auf, wann ein Foto eigentlich echt ist. Dieser Frage habe ich mich in der aktuellen Folge gewidmet. Und festgestellt, dass man sie gar nicht so einfach beantworten kann.
In der letzten Folge hatte ich erwähnt, dass es bei Samsung einmal einen Fall gab, bei dem Mondfotos durch Stockfotos ersetzt wurden. Doch das stimmt so nicht. In dieser Folge geht es um die Frage, was es mit den Mondfotos auf sich hat. Und dabei kommt auch zwangsläufig die Frage auf, wann ein Foto eigentlich echt ist. Dieser Frage habe ich mich in der aktuellen Folge gewidmet. Und festgestellt, dass man sie gar nicht so einfach beantworten kann.
Last, but not least
Die Kaffeekasse Die Anomalie und der Podcast sind kostenlos und entstehen in meiner Freizeit. Hauptsächlich, weil mir das viel Spaß macht. Ich habe aber eine kleine virtuelle Kaffeekasse auf der Plattform Ko-Fi und freue mich da über den ein oder anderen virtuellen Kaffee, den ich selbstverständlich zeitnah in ein koffeinhaltiges Heißgetränk umwandeln werde.
Twitch Einmal in der Woche bin ich live auf Twitch und rede da über die aktuellen Techniknews der Woche. In der Regel ist das der Mittwochabend.
Discord Im Discord gibt es immer mehr super nette Leute, die über spannende, witzige und teils auch ernste Themen diskutieren. Schau doch auch mal vorbei!
Themenvorschläge Welches Thema würde dich denn in einer der nächsten Ausgaben interessieren? Schreibs mir gerne als Antwort auf diese Email.
PS: Füge meinen Absender hallo@digitaleanomalien.de deinen Kontakten hinzu, damit der Newsletter auch zuverlässig bei dir ankommt und nicht im Spam landet.